2012 Data Discussion: Difference between revisions
From canSAS
(start Monday afternoon session) |
|||
| (15 intermediate revisions by 2 users not shown) | |||
| Line 1: | Line 1: | ||
= Report = | |||
[[2012 Data Working Group Report|Data Working Group Report]] | |||
= Minutes = | = Minutes = | ||
| Line 42: | Line 45: | ||
See: [[2012_Data_Discussion_Examples]] | See: [[2012_Data_Discussion_Examples]] | ||
== Monday Morning Plenary Session == | |||
These are rough notes collected from the morning plenary session. | |||
* work with multi-D data in Q space and other terms such as t, T, P, and ... | |||
* How might this standard be used? | |||
** Are there muti-technique analysis tools that can do simultaneous analysis? | |||
** Deposition format? | |||
*identify specific producers and consumers for standardization, especially high-volume: | |||
** SANSview (NIST) - agreed to work with us | |||
** Irena (APS) - agreed to work with us | |||
** Mantid (ISIS) - we will ask Mathieu Doucet | |||
** ImageJ plugins - Andrew Jackson will investigate | |||
*show how one might describe voxel size or boundaries | |||
**There various ways to do this. | |||
**Uncertainty, resolution and dimension are different. | |||
== Monday Afternoon Working Group Session == | == Monday Afternoon Working Group Session == | ||
* expect other standards group to supply dictionary of terms | * expect other standards group to supply dictionary of terms | ||
** start with dictionary from cansas1d/1.l0 standard | ** start with dictionary from cansas1d/1.l0 standard | ||
* Definition of Q is based on a cartesian coordinate as defined in the cansas1d/1.0 standard | * Definition of Q is based on a cartesian coordinate with the sample at the center as defined in the cansas1d/1.0 standard | ||
** (data | ** All Q objects when present must have the same shape (rank and dimensions) | ||
** At least one of these four data objects (Q, Qx, Qy, Qz) must be present | |||
** Q, when present, must be |Q| | |||
** Qx must be the Q component along the X axis | ** Qx must be the Q component along the X axis | ||
** Qy must be the Q component along the Y axis | ** Qy must be the Q component along the Y axis | ||
** Qz must be the Q component along the Z axis | ** Qz must be the Q component along the Z axis | ||
** | ** It is not clear if GISAXS geometries will work with this Q definition. Requires expert input from the community. It is thought that two SASdata groups will be used to describe the two Q mappings on the same intensity data. (Needs to be confirmed.) | ||
* Thus, we can drop the @Q attribute as redundant | |||
* transformation to/from other coordinate descriptions (such as from Peter Boesecke) is needed | |||
** IUCr CIF format has a generic mapping algorithm (ask Herbert Bernstein) | |||
* We must allow for multiple SASdata groups in a SASentry | |||
** This is easy for XML and makes for writing easy validation procedures. | |||
** HDF5 can't allow "SASdata" to be used as the object's name if more than one might be present. Needs a solution (NeXus chose one way to deal with this). | |||
* Andy Nelson (and others) asks about how to store Q resolution. | |||
** Is there a common way that is not burdensome to most cases? | |||
** Otherwise, we describe the type of case and then prescribe the parameters related. This is likely a bounded and not large set of cases. | |||
*** USAS might be slit-smeared (finite slit). Specify slit_length and perhaps slit length weighting profile. | |||
*** Kratky block-collimation cameras (infinite slit) have a set of parameters. | |||
*** pinhole geometry might be described by scalars or arrays. | |||
*** TOF-SANS may need its own parameters | |||
*** Can we define a numerical function to be applied? (represent this function as numerical data) | |||
* Data objects for I and Q may also indicate the uncertainty. The uncertainty is provided as another data object, the name of which is provided as an attribute to its parent, such as shown by Andy Nelson's reflectometry example. The shape of the uncertainty and its parent will be the same. Uncertainty will be represented as estimate of standard deviation unless specified otherwise. | |||
** The method for how the uncertainty was derived should be specified. An attribute (such as ''basis'') might be used with one of a list of possible short strings that describe the method. | |||
** The parent data object's ''uncertainty'' attribute is the default uncertainty for analysis. | |||
*** Any components of an uncertainty would be provided in a subgroup named as an attribute with components named. An example appears below. | |||
* Data objects for Q may indicate the volume of the element. Like the uncertainty above, the volume is provided as other data object or objects, the name of which is provided as an attribute to its parent. The shape of the volume is not necessarily the same as its parent. | |||
* For some representations of I, it may be necessary to represent the effect of a mask (to ignore this datum). The method is yet to be determined. | |||
** Here is an example mask: [[File:2012cansas-example-mask.png | 200px]] | |||
** In the most generic representation, this is easy. The masked data will be removed from the data set. | |||
** For gridded (such as image) data, the masked pixels must be indicated in some way. | |||
** To be consistent with the rule ''I represents data in absolute units or convertible to such by a scaling factor'', then the masked data must have a value of '''zero'''. To discriminate against actual I with value of zero, the uncertainty can be checked. A true masked datum must have an uncertainty of zero while an intensity is very unlikely to be zero exactly. | |||
** If we allow for an array to define the ''mask'', then we must relax the rule just described. '''We'll choose this.''' Value of 1 means keep this datum, value of 0 means remove this datum. | |||
** What is the shape (rank and dimensions) of the ''mask''? Describe through the use of '''mask_indices''' (as for Q and I). This means that the mask does not require the same shape as either Q or I. | |||
<pre> | |||
I : float[nI] | |||
@uncertainty="dI" | |||
dI : float[nI] | |||
@components="I_uncertainties" | |||
I_uncertainties: | |||
electronic : float[nI] | |||
@basis="Johnson noise" | |||
counting_statistics: float[nI] | |||
@basis="shot noise" | |||
secondary_standard: float[nI] | |||
@basis="esd" | |||
</pre> | |||
== Tuesday Morning Plenary Session == | |||
=== names of data objects === | |||
The names for data objects should follow a standard convention | |||
that starts with a letter (upper or lower case) and then letters, | |||
numbers, and "_". The length of the name is limited to no | |||
more than 63 characters (imposed by the HDF5 for names). | |||
This standard convention may be described by the regular expression: | |||
<pre> [A-Za-z][\\w_]* </pre> | |||
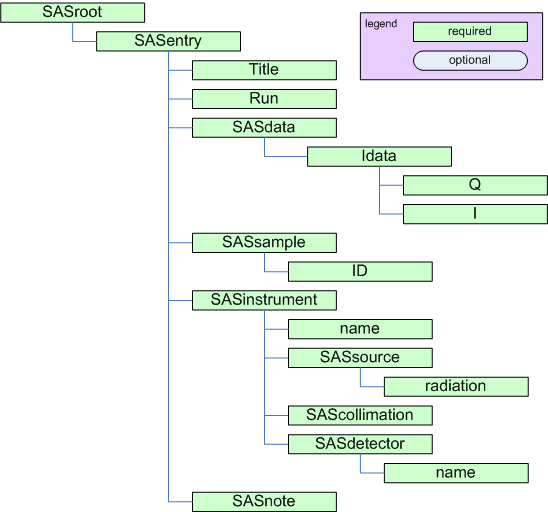
=== name of the SASdata group(s) === | |||
= Agenda with Discussion = | = Agenda with Discussion = | ||
| Line 77: | Line 158: | ||
}} | }} | ||
{{Comment | ARJN | Just as a matter of interest, why is it necessary to include transmission measurements for TOF instruments? Does the analysis depend on these values? Not saying it's not necessary, just wondering about why it is useful. | {{Comment | ARJN | Just as a matter of interest, why is it necessary to include transmission measurements for TOF instruments? Does the analysis depend on these values? Not saying it's not necessary, just wondering about why it is useful. | ||
}} | |||
{{Comment | SMK | Why do we already make provision to include the transmission value from a fixed-wavelength measurement?! First, they are an extremely value diagnostic tool for users and instrument scientists alike. Second, if you are going to provide the values you might as well do it in a way that keeps them with the data they produced and reduce the number of files the users have to take away. And, third, if you are seriously going to address resolution and multiple scattering issues as part of your analysis you will need the transmission data. | |||
}} | }} | ||
Latest revision as of 14:52, 6 August 2012
Report
Minutes
Saturday Afternoon Working Group Session
- Start with defining scope, what is reduced data?
- Eliminate all instrument geometry and detector effects.
- Will still need wavelength for anomalous x-rays
- Required:
- Intensity either in absolute units of cross section or directly convertible by a scaling constant
- Data described as a function of Q vector
- Uncertainty in intensity
- Wavelength and type of the probe radiation
- Resolution may be provided - how to represent it up for broader discussion.
- Keywords and verification tools - checking that correct tag names/attribute names have been used. Smarter than just saying yes/no.
- Defined a proposed minimum spec outline for discussion:
- Defined a proposed minimum recommended spec outline for discussion:
- (Compare with the 1D XML standard: media:cansas1d-v1-10-minimum.png)
Sunday Morning Discussion Session
- How many implementations?
- Need at least one reference implementation by end of meeting
- Shouldn't preclude multiple possible implementations. RG noted that if they follow the same data structure then they should be "trivially" interchangeable.
- SESANS? Spin-Echo? XPCS?
- Out of scope for our remit.
- Next step -> science examples.
- How to incorporate complimentary data e.g. uv spectra
- Space for calibration information
- Space for process data
Sunday Afternoon Working Group Session
- Based on morning discussion...
- Redefined a proposed minimum spec outline:
- Redefined a proposed minimum recommended spec outline:
- Redefined a proposed minimum spec outline:


- Generated a proposal for usage and format.
See: 2012_Data_Discussion_Examples
Monday Morning Plenary Session
These are rough notes collected from the morning plenary session.
- work with multi-D data in Q space and other terms such as t, T, P, and ...
- How might this standard be used?
- Are there muti-technique analysis tools that can do simultaneous analysis?
- Deposition format?
- identify specific producers and consumers for standardization, especially high-volume:
- SANSview (NIST) - agreed to work with us
- Irena (APS) - agreed to work with us
- Mantid (ISIS) - we will ask Mathieu Doucet
- ImageJ plugins - Andrew Jackson will investigate
- show how one might describe voxel size or boundaries
- There various ways to do this.
- Uncertainty, resolution and dimension are different.
Monday Afternoon Working Group Session
- expect other standards group to supply dictionary of terms
- start with dictionary from cansas1d/1.l0 standard
- Definition of Q is based on a cartesian coordinate with the sample at the center as defined in the cansas1d/1.0 standard
- All Q objects when present must have the same shape (rank and dimensions)
- At least one of these four data objects (Q, Qx, Qy, Qz) must be present
- Q, when present, must be |Q|
- Qx must be the Q component along the X axis
- Qy must be the Q component along the Y axis
- Qz must be the Q component along the Z axis
- It is not clear if GISAXS geometries will work with this Q definition. Requires expert input from the community. It is thought that two SASdata groups will be used to describe the two Q mappings on the same intensity data. (Needs to be confirmed.)
- Thus, we can drop the @Q attribute as redundant
- transformation to/from other coordinate descriptions (such as from Peter Boesecke) is needed
- IUCr CIF format has a generic mapping algorithm (ask Herbert Bernstein)
- We must allow for multiple SASdata groups in a SASentry
- This is easy for XML and makes for writing easy validation procedures.
- HDF5 can't allow "SASdata" to be used as the object's name if more than one might be present. Needs a solution (NeXus chose one way to deal with this).
- Andy Nelson (and others) asks about how to store Q resolution.
- Is there a common way that is not burdensome to most cases?
- Otherwise, we describe the type of case and then prescribe the parameters related. This is likely a bounded and not large set of cases.
- USAS might be slit-smeared (finite slit). Specify slit_length and perhaps slit length weighting profile.
- Kratky block-collimation cameras (infinite slit) have a set of parameters.
- pinhole geometry might be described by scalars or arrays.
- TOF-SANS may need its own parameters
- Can we define a numerical function to be applied? (represent this function as numerical data)
- Data objects for I and Q may also indicate the uncertainty. The uncertainty is provided as another data object, the name of which is provided as an attribute to its parent, such as shown by Andy Nelson's reflectometry example. The shape of the uncertainty and its parent will be the same. Uncertainty will be represented as estimate of standard deviation unless specified otherwise.
- The method for how the uncertainty was derived should be specified. An attribute (such as basis) might be used with one of a list of possible short strings that describe the method.
- The parent data object's uncertainty attribute is the default uncertainty for analysis.
- Any components of an uncertainty would be provided in a subgroup named as an attribute with components named. An example appears below.
- Data objects for Q may indicate the volume of the element. Like the uncertainty above, the volume is provided as other data object or objects, the name of which is provided as an attribute to its parent. The shape of the volume is not necessarily the same as its parent.
- For some representations of I, it may be necessary to represent the effect of a mask (to ignore this datum). The method is yet to be determined.
- Here is an example mask:
- In the most generic representation, this is easy. The masked data will be removed from the data set.
- For gridded (such as image) data, the masked pixels must be indicated in some way.
- To be consistent with the rule I represents data in absolute units or convertible to such by a scaling factor, then the masked data must have a value of zero. To discriminate against actual I with value of zero, the uncertainty can be checked. A true masked datum must have an uncertainty of zero while an intensity is very unlikely to be zero exactly.
- If we allow for an array to define the mask, then we must relax the rule just described. We'll choose this. Value of 1 means keep this datum, value of 0 means remove this datum.
- What is the shape (rank and dimensions) of the mask? Describe through the use of mask_indices (as for Q and I). This means that the mask does not require the same shape as either Q or I.
- Here is an example mask:

{kind=link}
{kind=link}
{kind=link}
I : float[nI]
@uncertainty="dI"
dI : float[nI]
@components="I_uncertainties"
I_uncertainties:
electronic : float[nI]
@basis="Johnson noise"
counting_statistics: float[nI]
@basis="shot noise"
secondary_standard: float[nI]
@basis="esd"
Tuesday Morning Plenary Session
names of data objects
The names for data objects should follow a standard convention that starts with a letter (upper or lower case) and then letters, numbers, and "_". The length of the name is limited to no more than 63 characters (imposed by the HDF5 for names).
This standard convention may be described by the regular expression:
[A-Za-z][\\w_]*
name of the SASdata group(s)
Agenda with Discussion
- The following is the agenda of work posted under business for canSAS-2012. Please add comments in the appropriate section below:
1D Format
Agree a proposed extension of the current 1D standard
- This is an extension proposed by Steve King (ISIS) that is required to enable, for example, t-o-f instruments to store auxillary wavelength-dependent non-I(Q) data in the same output files
Agree resultant changes to the "official" schema/stylesheet
SMK -For clarity, this extension was proposed after adoption of the existing version of the standard. Ratification of this extension at CanSAS-2012 would give facilities/software developers the necessary confidence to implement it.
SMK -This proposed extension would allow more-or-less any non-I(Q) data to be included in a CanSAS-1D data file under a suitable foreign namespace. That is remarkable flexibility, and it does not require any significant revision of the existing standard. However, it could be argued that certain types of non-I(Q) data are so integral to a SAS experiment that they should instead be given explicit SASXML tags within the standard? Transmission data is a good example of this: the existing standard explicitly includes a tag for the transmission value from a monochromatic measurement (SASsample\transmission) but makes no provision for transmission values from white beam measurements. The proposed foreign namespace extension will make such provision possible but only as an extension, not as a formal part of the standard. Is that acceptable? The downside of explicitly adding new SASXML tags to the existing standard is that it would require issuing a new version of the standard.
ARJN -I would recommend that during this meeting that the current format then be 'parked', the new 2D format should be flexible enough to handle 1D and 2D data.
SMK -Agreed.
ARR -Perhaps we should be cautious about suggesting no further development for the existing 1-D format. Unless there is scope for adapting to future needs, it will be seen as not suitable for new uses. This, of course, does not imply that there have to be active plans for further changes at present.
AJJ -As to this particular case, I suggest that since SMK and I have it done, that we accept the additional tags, call it v1.1 and move on. If other extensions arise later and become "widely" used, then we can incorporate them as they arise. This is the key benefit of using an extensible format.
ARJN -Just as a matter of interest, why is it necessary to include transmission measurements for TOF instruments? Does the analysis depend on these values? Not saying it's not necessary, just wondering about why it is useful.
SMK -Why do we already make provision to include the transmission value from a fixed-wavelength measurement?! First, they are an extremely value diagnostic tool for users and instrument scientists alike. Second, if you are going to provide the values you might as well do it in a way that keeps them with the data they produced and reduce the number of files the users have to take away. And, third, if you are seriously going to address resolution and multiple scattering issues as part of your analysis you will need the transmission data.
2D Format
Define minimum information necessary for reduced data
- definition of what reduced data is and hence the problems we should address.
- review previous discussions on 2D
- considerations specific to 2D reduced data
- consider forward looking issues such as
- grazing incidence
- event mode analysis
Suggest format framework
- NeXus extension, canSAS 1D extension, other, with brief discussion of the reason for the choice (including options considered, pros and cons of each, and final weighing)
- A proposal for a 2D version of the canSAS 1D data format has been posted for discussion: 2D Data Format Proposal
- NeXus has a definition for multi-dimensional data:
ARJN -Having looked at both those Nexus definitions it is not clear to me how:
- multiple detectors are handled.
- What happens if the detector pixels are not grid shaped?
- how does one stuff multiple datasets (e.g. from event mode acquisition)?
Remember, all we need is instrument independent information in this file, nothing else.
- Andyfaff 12:45, 27 July 2012 (CDT)
- James Hester (an expert in the CIF format) has compelling ideas on the subject of common data files. CIF format notes Hester
- Andrew Nelson has commented via email exchange with Adrian Rennie : Notes on Reduced Data formats with examples from reflectometry
- Ron Ghosh has laid out details of a proposal to use HDF5/Nexus : HDF5 Notes Ghosh
- Peter Boesecke misses definitions of parameters that are needed to describe small-angle and wide-angle scattering experiments. Parameters like "Distance", "Center", "Rotation" have only a meaning when they are part of a geometrical model, otherwise they are useless. He has collected parameters that are required for SAS/WAS experiments with position sensitive detectors (1D and 2D). When saving experimental data it should be checked that these parameters are either implicitly or explicitly described by the supplied metadata: SX_parametrization.
- Jerome Kieffer sent the following to consider: Jerome Kieffer Mail